How to Train a GPT From Scratch
An experiment reproducing NanoGPT and lessons learned
- Jan. 24, 2024 by
- Akash Kundu
In the realm of artificial intelligence, we hear a lot about AI-powered Large Language Models (LLMs) like ChatGPT, Bard, Gemini, and others. Many of these models rely on a technology called Generative Pretrained Transformers (GPTs). GPTs are a type of LLM that use deep learning to produce natural language texts based on a given input. A user of the GPT will feed the model with input (like a sentence of text). The GPT then generates text based on information extracted from publicly available datasets. These GPTs can process a wide range of text inputs from long-form paragraphs and code to creative writing. They provide insights, analysis, and summaries based on the input given. Figure 1 shows the architecture of a GPT.
![]()
Figure 1: Transformer Architecture
My Chameleon experiment, which I prepared during my participation in Chameleon's Virtual Reproducibility Hackathon in Dec. 2023, aims to reproduce the results of NanoGPT, an analysis by Andrej Karpathy to train a character-level GPT from scratch on the works of Shakespeare. The code is simple and easy to understand. In my experiment, I fine-tune the gpt2-xl model on the same Shakespeare dataset using 1 Nvidia A100 GPU on Chameleon Cloud and visualize the results in a Jupyter Notebook.
Research Overview
The aim of my experiment is to help people to get their feet wet in GPTs. Training a GPT is highly resource-intensive, which unforutnately deprives most enthusiasts of the opportunity ever to try such a project. Thanks to the resources that Chameleon offers, this barrier to working with GPTs can be overcome. My reproduction of NanoGPT and the results I obtain highlight the importanance of reproducibility in research and will hopefully help researchers better understand the existing work. NanoGPT is the simplest version of a GPT that helps us understand the foundation of the current LLMs.
In my experiment, I followed the methodology of Andrej Karpathy’s NanoGPT and achieved similar results. I was careful to ensure that the experiments were as similar as possible. Hence, for the gpt2-xl fine-tuning experiment, I utilized 1 A100 as specified in Karpathy's analysis. Karpathy had taken into consideration that most users may not have access to GPUs, hence he also published a CPU-based version of the project, which I also reproduced. Changing the parameters of the model significantly improved the loss during the CPU-version of the experiment from 1.88 (in the actual experiment) to 1.54.
My hope is that researchers can build on my replication of NanoGPT. For example, researchers could try to reproduce the results, change the parameters for themselves (to possibly improve the model), or also use their own dataset to train their model or fine-tune any version of gpt2 (small, medium, large, xl) and do a comparative analysis. They could even try to extend the work by using 8 A100s to pre-train GPT2 with OpenWebText (which is the closest representation of what GPT2 was trained upon) and compare the results with actual GPT2’s reported results. For seasoned researchers, trying out and adding Fully Sharded Data Parallel (FSDP) instead of Direct Data Parallel (DDP) could be an interesting experiment as well.
Running the Experiment
I developed a Jupyter Notebook to replicate the experiment, which I shared as a packaged artifact on the Chameleon Trovi service. (Trovi is a service for packaging and sharing experiment artifacts that use Chameleon hardware. You can also apply for special badges to highlight your work on the service. For example, I received a REPETO reproducibility badge for my artifact. See the REPETO website for more information about how to obtain this badge.) I encourage readers to try running my notebook analysis and explore changing different parameters or even running the experiment on other hardware types. Figure 2 shows a screenshot from the notebook.
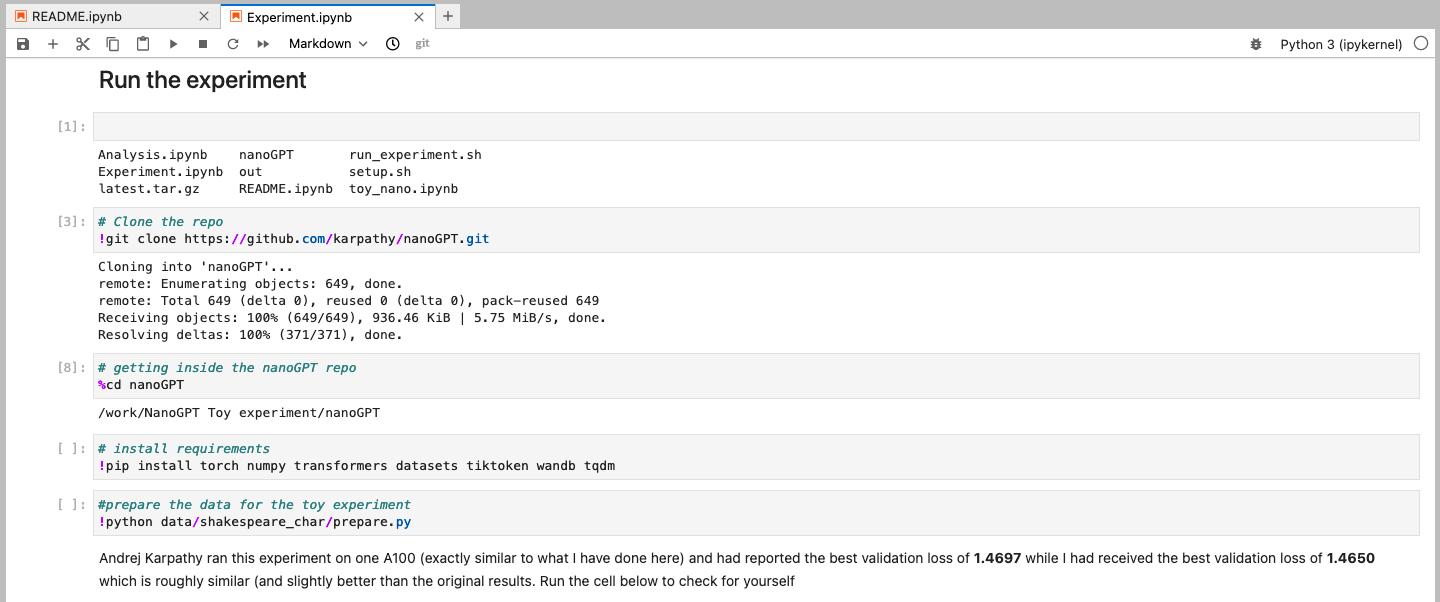
Figure 2: Demonstrating the experiment artifact that I created to replicate the NanoGPT analysis.
Simply running all the cells of my notebooks should be enough to replicate the experiment. Reserving a bare-metal node that has 1 A100 GPU is required. You can check node availability for this GPU on Chameleon Cloud's hardware catalog. I also tried to reproduce the results of gpt2 with a compute_liqid node from CHI@TACC, which I wanted to reconfigure to an 8xA100 cluster. I have previously worked with Google Colab but Colab's hosted runtime has caused me issues in the past. I didn’t have to face these issues with Chameleon Cloud.
User Interview
Chameleon: Tell us a bit about yourself!
I am Akash Kundu, a second-year CS undergraduate from Heritage Institute of Technology, Kolkata, India. I am currently an AI Research Fellow at Apart Research, where I am co-authoring a paper on cross-lingual robustness of alignment techniques and evaluations on state-of-the-art large language models. I like to look at data and generate insights out of it. When I am not researching/building ML models/studying for my classes, you can find me singing and playing my guitar. I aim to be an Alignment Researcher who figures out the flaws in AI systems and aligns AI towards the right goals to make them safer for the community.

(A picture of me teaching a tech session as the Google Developers Students’ Club AI/ML Lead at my institute.)
Chameleon: What is the most powerful piece of advice you have for students beginning research or finding a new research project?
"Good things take time. Trust the Process."
Research is not a sprint, it’s a marathon. I would like to share one of my favourite tweets from Andrej Karpathy.
“How to become expert at a thing:
1) iteratively take on concrete projects and accomplish them depth wise, learning “on demand” (ie don’t learn bottom up breadth wise)
2) teach/summarize everything you learn in your own words
3) only compare yourself to younger you, never to others”
Chameleon: Are there any researchers whom you admire? Why?
If it’s not already evident from my blog post, I really admire (you guessed it) Andrej Karpathy. This man had a lot of impact on the whole ML community and he has shared his knowledge with the world openly as well which is very inspiring. I have learned a lot from his CS231n Stanford Course on Deep Learning that he has publicly shared on his youtube channel. He took the time to be the human benchmark for ImageNet to prove that neural networks can work better than humans in certain instances which was very fun to know about.
In the Alignment Space, there is Neel Nanda who has done a lot of work in the field of Mechanistic Interpretability and has tried extremely hard to provide roadmaps and resources for people who want to get started with Mechanistic Interpretability.
Research should take us forward and help the whole community. The amount of time that these people have put in to educate and also create an impact in the field inspires me and I would love to be a researcher who’s known for his work (someday).
Chameleon: Why did you choose this direction of research?
The amount of people who should care about AI Safety and work in the field of AI Alignment is 1000x lower than it should be. The growth of AI is exponential and we need more and more people to understand the models deeply before scaling them to avoid deceptively trained models or scalable oversights. This field is in its infancy and I feel that I could create a lot of impact by getting into this field.
Chameleon: Have you ever been in a situation where you couldn’t do an experiment that you wanted to do? What prevented you from doing it?
I have wanted to conduct a lot of experiments but have left them after calculating the GPU costs. Reproducing NanoGPT was one of them which was finally done (thanks to Chameleon!). Currently, I have a plan to educate people in my college about stable diffusion to generate images and show them how to fine-tune SDXL. I plan to get started on this right after my semester ends!
Chameleon: Thank you for sharing your knowledge with the Chameleon community!
Reproduce, Rerun, Repeat: The Fun Way to Learn Machine Learning!
- March 28, 2023
This month's user experiment blog discusses a group's experience in reproducing machine learning research on Chameleon!
Automated Fast-flux Detection using Machine Learning and Genetic Algorithms
- May 23, 2022 by
- Ahmet Aksoy
Interested in protecting remote devices from malicious actors? Learn about how a researcher at the University of Missouri is approaching this problem with genetic algorithms and host fingerprinting! Also included is a YouTube video where Dr. Aksoy discusses this research.
Announcing Virtual Reproducibility Hackathon – December 15th, 2023 – HOLD THE DATE
Learning how to produce reproducible experiments on Chameleon
- Nov. 13, 2023 by
- Marc Richardson
We are excited to announce our Virtual Reproducibility Hackathon taking place on Friday, December 15th, 2023! See the details below for more information.
No comments