Reproduce, Rerun, Repeat: The Fun Way to Learn Machine Learning!
- March 28, 2023
By: Chandra Shekhar Pandey, Priyanka Bose
What is the central challenge/hypothesis your experiment investigates?
We used Chameleon to investigate the reproducibility of a published result in machine learning. It started in Prof. Fraida Fund’s course at NYU Tandon on Introduction to Machine Learning, where as part of the course, we had to do a project in which we reproduced a published result in machine learning. For our project, we reproduced some results related to the paper: J. Shen et al., "Natural TTS Synthesis by Conditioning Wavenet on MEL Spectrogram Predictions," 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 2018, pp. 4779-4783, doi: 10.1109/ICASSP.2018.8461368.
Toward the end of the course, she made an announcement about the ML Reproducibility Challenge, and we grabbed the opportunity to participate in order to familiarize ourselves more with this area of research.
So, we used Chameleon to participate in the ML Reproducibility Challenge. The main objective of this challenge is to promote the publication and exchange of trustworthy, reproducible scientific discoveries. Participants are supposed to investigate the reproducibility of papers accepted for publication at prestigious machine learning conferences - they reproduce the computational experiments in the paper, either using a new implementation or the code/data or other information provided by the authors, in order to verify the empirical results and claims made in the paper.
How is your research addressing this challenge?
As part of the ML Reproducibility Challenge, participants write a reproducibility report describing the "easy parts" and "hard parts" of reproducing the work that they chose. These reports, and all the code to go along with them (including in our case, code to reserve resources and execute the experiment on Chameleon!) will be published alongside the report, if the submission is accepted.
We picked one ML conference paper from 2022 and tried to reproduce its main claim. Since our submission is currently under double blind review, we won't share more details right now. But, we can speak generally about what we understood about reproducibility from participating in this challenge!
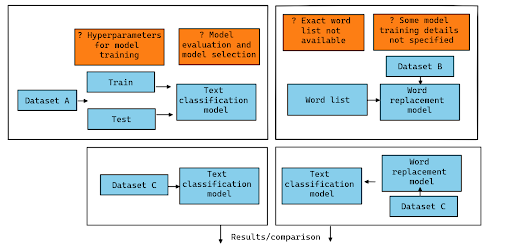
The most challenging thing we encountered in the paper we had picked to reproduce was that the instructions in the original paper had us assume a lot of the details in our own implementations. (We tried to illustrate this in the diagram shown above.) We tried a few different variations of what we understood the original authors to have done, to see if one of them would "match" the original results. We actually found that the result overall was reproducible but that the magnitude of the effect depends a lot on those decisions that were not well specified in the paper.
For our course project, the claims we were trying to validate were qualitative claims about specific text strings supplied by the authors in supplementary material. In this case, we used pre-trained models, so we didn't have to guess what the authors had done. However, for the test samples where our results did not agree with the original authors' claims, we couldn't go any further to explore the difference.
How do you structure your experiment on Chameleon?
What features of the testbed do you need in order to implement your experiment?
For our experiments, we utilized Google's Colab as our main interface, since we were familiar with it from our coursework. It is integrated with our existing Google Drive setup, and makes collaboration really easy. Also, it's very fast to get started on a project with Colab's hosted runtime. For some parts of our work that weren't affected by Colab's limitations, we could work directly on their hosted runtime on an ad-hoc basis, without having to take the time to reserve resources and set them up.
But, Colab's hosted runtime has some limitations that make it impractical for this challenge - limited GPU access, limited storage, and limited ability to install and use specific Python or Python library versions. For example, when working on the ML Reproducibility Challenge, the Colab hosted runtime did not have enough RAM to work with large data sets efficiently. We also did not have predictable GPU access with the Colab hosted runtime, since GPUs are allocated based on past usage and current usage patterns. In both the course project and the ML Reproducibility Challenge, there were open source implementations of the models we were working with that we were not able to run on the Colab hosted runtime, because they needed specific Python or Python library versions that could not be installed on Colab. Even between submitting the course project and packaging it for Trovi, there were changes in the default Colab environment and we had to figure out how to get the library versions we needed to make our code work again.
So, we opted to use Chameleon's bare metal Ubuntu server with an RTX6000 GPU on CHI@UC as our remote runtime, and connected the Colab interface to this runtime. The process of connecting Colab to Chameleon's GPU was described in the Trovi item "Connect Google Colab to a server on Chameleon", and is illustrated in the following diagram:
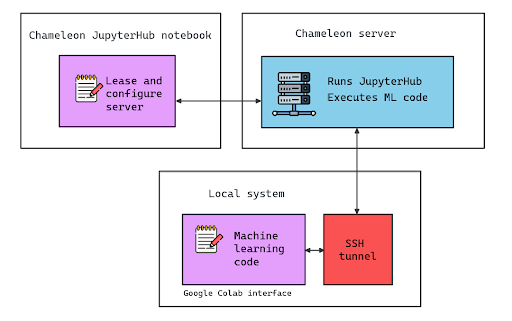
Step 1: We use Chameleon's JupyterHub to lease and configure a server with GPU. Our notebook then sets up our instance with the specific driver version, version of Python, and Python libraries that the experiment needs. Then it starts a JupyterHub server on the instance and gives us an SSH command we can use to establish a tunnel between our local system and the JupyterHub service on our instance.
Step 2: We use this SSH command on our local terminal to establish a tunnel.
Step 3: We open a Python notebook on Google Colab, but instead of connecting to the “hosted runtime” of Colab, we asked it to connect to a “local runtime” by using the JupyterHub URL that we got in step 1. This way, the code in the Colab notebook is executed on our Chameleon server, with all the advanced capabilities and specific configuration required by our experiment.
Can you point us to artifacts connected with your experiment that would be of interest to our readership?
We packaged our Intro ML course project as an example of this approach - you can try it out in this Trovi artifact.
Tell us a little bit about yourself.
Shekhar

As a Master's student in Computer Engineering at New York University Tandon School of Engineering, my academic focus is on Machine Learning, Deep Learning, and Natural Language Processing. My goal is to make a significant impact in the field of Large Language Models. When I'm not studying, I enjoy following Cricket, a sport that is greatly celebrated in my home country.
Priyanka

I am currently pursuing my Master of Science degree in Computer Engineering from New York University, Tandon School of Engineering. I have worked for ServiceNow in the past, after finishing my undergraduate studies in 2018. My academic focus is on Cloud Computing and Distributed Systems and its alignment with the field of Machine Learning. I hope to build a business with a major social impact one day. My interests and hobbies include exploring
places, meeting new people and learning about their backgrounds.
How do you stay motivated through a long research project?
Shekhar: Maintaining motivation during an extensive research project can be difficult, but I found some tactics that were effective for me. By breaking down the project into smaller, more feasible tasks, I was able to maintain momentum and monitor my progress. Additionally, I sought regular feedback from my mentors to ensure that I was moving in the right direction.
Priyanka: Social impact is something that always pushes me to do better. I try to work on projects that will produce results that are useful to the community in general. Knowing that the end result of my project might be of help to someone else, keeps me motivated to do better. I also communicate with my project partner(s) and my mentors a lot about the work I’m doing, as well as hear what they’ve been doing so far, and that helps with tracking progress and keeps me on my toes.
Are there any researchers you admire? Can you describe why?
Shekhar: As a child, I was always fascinated by A.I and have come to admire numerous researchers for their significant contributions to the field. However, if I had to choose just a few, it would be Alex Krizhevsky and Andrej Karpathy. What I find most admirable about these two giants is their ability to simplify complex concepts, which is exemplified in their work. For instance, Alex Krizhevsky's development of AlexNet was a pivotal moment in computer vision research and made the field more accessible to other researchers. Similarly, Andrej Karpathy's leadership of the A.I team at Tesla was instrumental in bringing about the era of self-driving cars, making this technology more practical and easier for people to understand. Overall, my appreciation for these researchers is a reflection of their impact on advancing the field of A.I and their ability to make sophisticated ideas more comprehensible to others.
What has been a tough moment for you either in your life or throughout your career? How did you deal with it? How did it influence your future work direction?
Priyanka: My father is a retired Indian Army officer and my mother is a retired school teacher. Ever since when I was a child, I was molded to work for the society at large. Having moved around a lot as a child, I have experienced firsthand the challenges that diversity brings. Overtime, I’ve realized that difference is not a hindrance to understanding. One of the biggest things I did to deal with the diversity was to adapt, be it learn a new language or try to understand and learn mannerisms.
That is why in my works, I always try to mitigate the issues that arise with differences. Just because people might speak different languages, it doesn’t change the core fundamentals of what being a human being is.
No comments