NetPrompt: AI-Powered Network Policy Management for Programmable Networks
Using Large Language Models to Automate P4 Policy Generation for Dynamic Software-Defined Networks
- Dec. 22, 2025 by
- Kevin Kostage Kostage
Modern networks are growing increasingly complex, and managing them effectively requires sophisticated policy configurations that can adapt in real-time. For applications like high-definition video streaming or social virtual reality, maintaining Quality of Service (QoS) and Quality of Experience (QoE) under dynamic conditions is critical—but it's also incredibly challenging. The problem becomes even more complex when working with P4 (Programming Protocol-independent Packet Processors), a language that enables direct programmability of network data planes.
While P4 offers unprecedented control over packet processing, it comes with a steep learning curve. Writing P4 code requires specialized expertise in protocol parsing, match-action pipelines, and hardware constraints. Even minor errors can lead to network outages, misrouting, or security vulnerabilities. This raises a crucial question: can we automate the generation of these complex network policies while ensuring they're correct, efficient, and adaptable?
NetPrompt is a novel framework that harnesses the power of Large Language Models (LLMs) to automatically generate and optimize P4 scripts for Software-Defined Networks (SDN). By combining prompt engineering with structured model refinement, NetPrompt translates high-level network requirements into production-ready P4 configurations—achieving up to 50% lower latency and 25-40% higher throughput compared to existing frameworks.
Research Overview
The challenge NetPrompt addresses is multifaceted. SDN environments require adaptive policy generation to ensure satisfactory QoS and QoE expectations under constantly shifting network conditions. While generative AI shows promise for automating network configuration, there's been a notable gap in methods for AI-driven policy automation—particularly when it comes to translating high-level network intent into suitable Service Function Chains (SFCs) using P4 switch configurations without introducing misconfigurations.
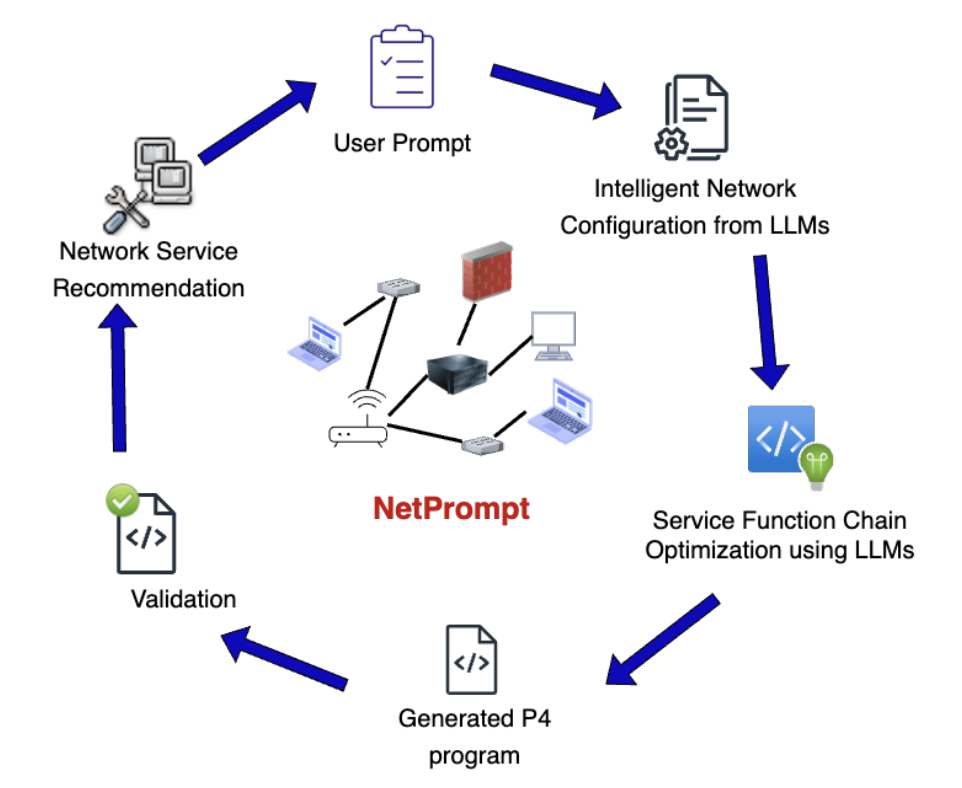
NetPrompt's solution centers on a three-phase cyclic architecture. First, the LLM-Driven Policy Synthesis Phase generates structured P4 scripts using pre-trained LLMs fine-tuned with P4 best practices through in-context learning. The system begins with user-provided prompts specifying network behavior in terms of QoS and QoE requirements, then extracts key components like desired behavior, protocols, and forwarding rules. These extracted intents form the basis for constructing Service Function Chains—ordered sequences of low-level programmable network functions such as traffic classification, header rewriting, and packet tagging.
The second phase, Prompt Engineering with a Vectorized Database, refines policies through adaptive prompt selection and retrieval-augmented learning. The researchers evaluated multiple prompting strategies—Zero-Shot, Few-Shot, Chain-of-Thought, Meta-Prompting, and Self-Consistency—finding that Self-Consistency prompting achieved the highest accuracy (95% syntax accuracy, 92% execution validity) while reducing error rates by 50%. The vectorized database stores validated P4 configurations as dense vector embeddings, enabling efficient retrieval of structurally relevant past configurations and reducing redundant computations.
Finally, the Cyclic Validation Process ensures AI-generated policies undergo continuous refinement through both offline simulation and online testbed validation. Policies are first tested in controlled environments, then deployed to real-world testbeds where they're assessed under realistic traffic loads and congestion scenarios. This feedback loop enables NetPrompt to adaptively fine-tune its configurations for robustness under dynamic network conditions.
A key innovation is NetPrompt's strategic use of multiple LLMs based on task requirements. After extensive benchmarking, the researchers selected Claude Sonnet 3.7 as the primary model for policy generation due to its near-100% correctness across tasks, highest code readability, and superior edge case handling. For scenarios requiring faster iteration with acceptable reliability, DeepSeek-R1 serves as a secondary option with faster execution speeds.
Experiment Implementation on Chameleon
NetPrompt's validation required a sophisticated, geographically distributed testbed infrastructure—and Chameleon Cloud proved essential to the research team's success. The online experiments were conducted across a multi-cloud architecture integrating both Chameleon and FABRIC resources, with three primary environments: the HPC Cloud at CHI@TACC in Texas, the Transmission Cloud at CHI@UC in Illinois, and an Edge Cloud connected via Starlight.
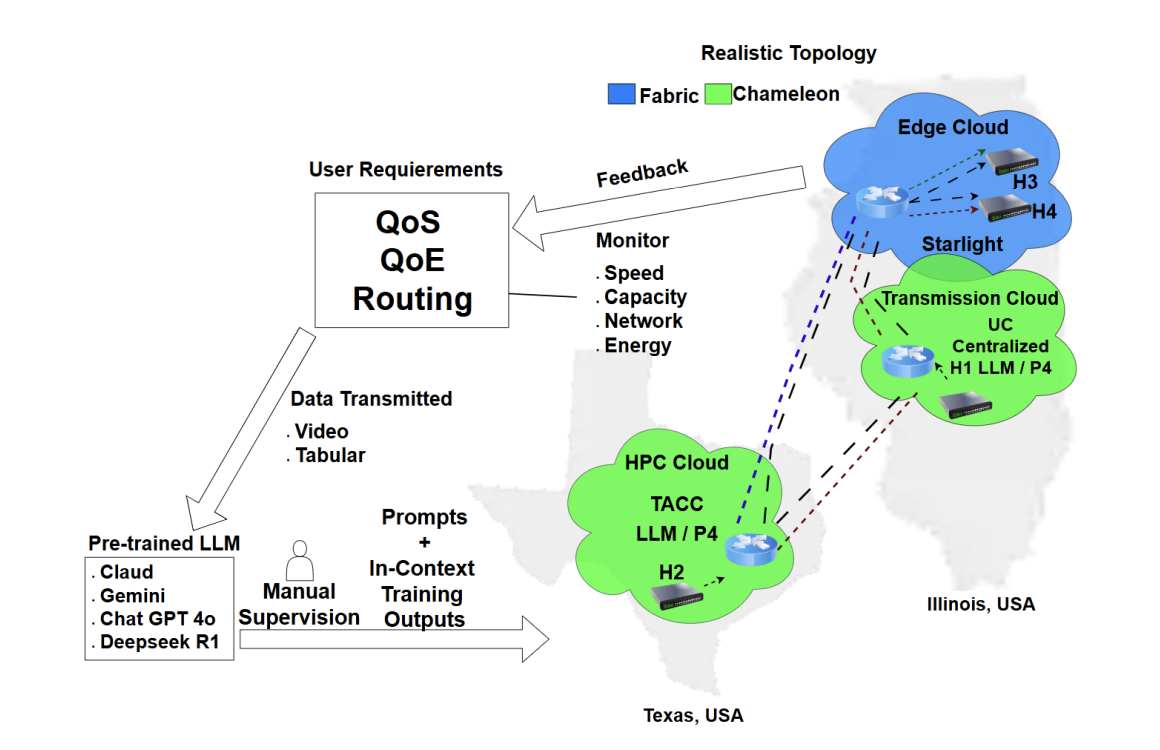
The HPC Cloud at TACC served as a computational hub where LLM-based policy synthesis and refinement were executed, while the Transmission Cloud at UC acted as a centralized control plane, hosting LLM-driven P4 decision-making for optimized routing and traffic prioritization. The Edge Cloud interfaced directly with end-hosts, enabling real-time network adaptation based on feedback-driven policy adjustments.
Chameleon's bare-metal access was critical for deploying P4-programmable switches and ensuring controlled, reproducible test conditions. The team relied on Chameleon's hardware catalog for resource selection and utilized the platform's multi-site networking capabilities to construct practical network topologies. The distributed nature of Chameleon's infrastructure—spanning multiple geographic locations—allowed the researchers to test NetPrompt under realistic wide-area network conditions, evaluating performance metrics such as latency, throughput, and packet loss.
The validation workflow involved an iterative feedback loop. The team transmitted various data types, including video streams and tabular datasets, to simulate real-world network traffic. Pre-trained LLMs were used for in-context training with manual supervision to ensure alignment with network constraints. NetPrompt-generated P4 policies were deployed across the topology, and real-time telemetry ensured adherence to QoS/QoE objectives while continuously feeding back into the LLM model through prompt engineering.
For offline validation, the researchers used Mininet in a virtualized SDN environment on AWS EC2, testing both simple two-host topologies and more complex triangular configurations with three P4 switches to evaluate rerouting capabilities during simulated link failures.
Results and Impact
NetPrompt's performance exceeded expectations across multiple metrics. In online experiments focusing on packet forwarding and rerouting for video streaming applications, NetPrompt achieved notably lower latency than both Lucid 2.0 and Lyra, closely approaching Oracle-level performance from human-written P4 scripts. The latency distribution was also tighter, indicating more consistent responsiveness during packet delivery.
Most impressively, NetPrompt recorded the highest throughput of all tested approaches—surpassing even the Oracle baseline in some scenarios. This demonstrates that LLM-generated policies can not only match human expertise but sometimes exceed it by discovering optimizations that might not be immediately obvious to expert programmers.
In terms of code generation quality, Claude Sonnet 3.7 consistently achieved near-100% correctness across packet forwarding, dropping, and rerouting tasks, with the highest code readability scores (up to 9.2 out of 10) and lowest cyclomatic complexity. The Self-Consistency prompting method proved most effective, achieving 95% syntax accuracy and 50% error rate reduction compared to simpler approaches.
The real-world implications are significant. NetPrompt substantially reduces misconfigurations in network policy management, making programmable networks more accessible to practitioners who may not have deep P4 expertise. For applications like video streaming that require dynamic QoS/QoE optimization, NetPrompt enables automated, adaptive policy generation that maintains stable performance under changing network conditions—without manual intervention.
Experiment Artifacts
The NetPrompt team has made their work fully reproducible. All code and scripts used in the experiments are available in the NetPrompt GitHub repository. The research paper, "NetPrompt: LLM-driven Programmable Network Policy Management and Optimization," was published at the 2025 34th International Conference on Computer Communications and Networks (ICCCN) (available here).
About the Research Team
This work represents a collaboration between researchers at the University of Missouri - Columbia and Florida Gulf Coast University. The team includes Kiran Neupane, Ashish Pandey, and Prasad Calyam from Missouri, along with Kevin Kostage, Sean Peppers, and Chengyi Qu from Florida Gulf Coast. Their research focuses on programmable networks, SDN optimization, and the intersection of artificial intelligence with network infrastructure management.
The NetPrompt project is supported by the U.S. Army Corps of Engineers, Engineering Research and Development Center—Information Technology Laboratory (ERDC-ITL) and the National Science Foundation (NSF). Looking ahead, the team plans to enhance code generation accuracy by expanding P4 training datasets, extend NetPrompt to support dynamic security policy adaptation through integration with intrusion detection systems, and test the lightweight deployment framework across diverse edge environments including IoT devices, drones, and HPC nodes.
Thank you for sharing your work with the Chameleon community!
Detecting the Invisible: Machine Learning for Cloud Infrastructure Health
- Nov. 17, 2025 by
- Syed Mohammad Qasim
Keeping large-scale cloud systems running smoothly requires catching problems before they become outages. Learn how Chameleon User Syed Qasim developed an efficient anomaly detection system for Chameleon Cloud's OpenStack infrastructure.
Introducing MINCER’s Performance Measurement and Reproducibility Appliance
Building a Standardized Framework for Reproducible Performance Measurements Across Diverse HPC Architectures
- Oct. 31, 2025 by
- Gonzalez, Jhonny
Reproducibility is a cornerstone of scientific computing, yet achieving consistent results across different hardware environments remains a significant challenge in HPC research. The MINCER project tackles this problem head-on by providing researchers with an automated performance measurement appliance on Chameleon Cloud. Using Docker containers and the PAPI framework, MINCER enables standardized collection of performance metrics across CPUs, NVIDIA GPUs, and AMD GPUs, making it easier to compare results and understand how system-level factors influence computational performance. This post explores how MINCER is helping make HPC experiments more reproducible and accessible to the research community.
Chameleon Authentication Demystified: Common Issues and Solutions
Navigating Federated Identity, Multiple Accounts, and Common Pitfalls
- Sept. 15, 2025 by
- Paul Marshall
Don't let authentication problems derail your research momentum. This practical guide demystifies Chameleon's login system and arms you with clear, step-by-step solutions for the authentication challenges that frustrate users most. Learn to confidently navigate multiple accounts, identity provider changes, and stubborn login issues.
Tigon: A Distributed Database for a CXL Pod
Leveraging Shared CXL Memory to Break Through Traditional Network Bottlenecks
- Aug. 27, 2025 by
- Yibo Huang
Traditional distributed databases are often slowed down by network communication overhead. The Tigon project introduces a new database design that tackles this bottleneck using Compute Express Link (CXL), a technology that allows multiple computer hosts to access a shared memory pool. Tigon employs a hybrid approach, keeping most data in fast, local host memory while moving only actively shared data to the CXL memory. This results in significant performance gains, achieving up to 2.5 times higher throughput than traditional databases. Since the multi-host CXL hardware required for this research was not yet commercially available, the project was brought to life by emulating the next-generation environment on Chameleon's bare-metal servers.
No comments