Detecting the Invisible: Machine Learning for Cloud Infrastructure Health
- Nov. 17, 2025 by
- Syed Mohammad Qasim
Cloud computing systems power everything from online services to AI applications, and even brief outages can result in substantial losses. For a research testbed like Chameleon that serves over 13,000 users across more than 1,300 projects, maintaining system reliability is critical. But how do you detect problems in complex cloud infrastructure before they impact users?
Research Overview
This research tackles a fundamental challenge in cloud operations: detecting anomalies in OpenStack control plane services before they cascade into system-wide failures. Traditional approaches to anomaly detection require enormous amounts of training data and computational resources. The researchers asked: can we build an effective anomaly detection system that's both accurate and practical to deploy?
Working with real operational data from Chameleon Cloud's multi-site infrastructure, the team developed and evaluated machine learning models that can identify unusual behavior patterns in cloud services. They collected high-resolution metrics every 15 seconds from services like Nova, Neutron, Keystone, and Glance across both the CHI@UC and CHI@TACC sites, creating the first publicly available dataset of OpenStack control plane resource usage.

The researchers tested four state-of-the-art unsupervised time series models—TranAD, Prodigy, USAD, and OmniAnomaly—to see how well they could detect real infrastructure issues. Their key finding: training with just three days of healthy system data strikes the optimal balance between training cost and detection accuracy. All four models achieved high F1 scores, demonstrating that practical, efficient anomaly detection is achievable for production cloud systems.
Experiment Implementation on Chameleon
Chameleon's unique multi-site OpenStack architecture made it an ideal testbed for this research. The team leveraged the existing observability infrastructure that collects node-level performance metrics using Prometheus and container-level metrics via cAdvisor. This provided detailed resource usage data including CPU, memory, disk, and network metrics at 15-second intervals.
The research required analyzing metrics from actual operational incidents spanning several months. The researchers documented and labeled seven real anomalous events, including certificate expiration automation failures, network uplink issues blocking dashboard access, OpenStack version upgrades causing service disruptions, and resource exhaustion from smoke test failures.
Chameleon's bare-metal architecture presented an interesting constraint: the team couldn't collect resource usage from hypervisors or tenant compute hosts due to isolation requirements. However, this limitation actually reflects real-world cloud deployments where provider infrastructure and tenant workloads must remain separate.
Key Findings
The experiments revealed several important insights for cloud operators. Models trained on just 3 days of data performed nearly as well as those trained on longer periods, achieving F1 scores above 0.85. This dramatically reduces the computational cost and time needed to deploy anomaly detection systems.
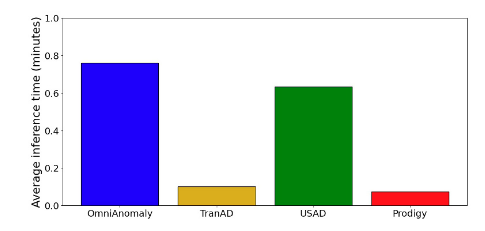
While all four models performed well, each had different strengths. TranAD excelled at overall accuracy, while USAD provided better balance between precision and recall. For operators concerned about false positives disrupting on-call teams, models with higher precision may be preferable.
The research also highlighted how real anomalies are complex—some incidents showed clear metric deviations (like the OpenStack upgrade affecting all services), while others were subtle (smoke test failures with no significant metric changes). This underscores why traditional threshold-based alerting alone isn't sufficient for modern cloud infrastructure.
Experiment Artifacts
The complete research is published at the IEEE International Conference on Cloud Engineering (IC2E) 2025. The team also released their labeled dataset publicly, providing the cloud research community with real operational data for developing and benchmarking anomaly detection approaches.
This work demonstrates how research testbeds like Chameleon not only support experiments on cloud infrastructure, but can also serve as living laboratories for improving cloud operations themselves. The anomaly detection techniques developed through this research are now being integrated into Chameleon's monitoring infrastructure to help maintain service reliability for the user community.
About the Researchers

Syed M. Qasim is a PhD student at Boston University working at the intersection of cloud systems and machine learning. His research focuses on making large-scale distributed systems more reliable and efficient through intelligent monitoring and automation. This project brought together his interests in both machine learning and practical systems engineering, collaborating with the Chameleon operations team to understand real-world infrastructure challenges. Before pursuing his PhD, Syed served as a Manager of Platform Engineering at State Street, where he helped to setting up their API management and DataRobot platforms. Additionally, he worked as an Application Developer at ThoughtWorks, where he helped build the VAKT platform.
Less Data, Better Results: How Active Learning Improves Workflow Anomaly Detection
Chameleon-Powered Research Shows the Path to Efficient Scientific Computing
- Feb. 26, 2025
Scientific workflows often fail in unexpected ways, but traditional detection systems require massive amounts of training data. This groundbreaking approach generates just the right data needed to train anomaly detection models, improving accuracy while reducing resource consumption.
All About Traces
- March 9, 2020 by
- Zhuo Zhen
The workload traces from data centers facilitate research on the design of computer systems, job scheduling, and resource management. Researchers can analyze the traces and replicate real-life workloads for their experiments. In this blog, we will briefly review some major released traces and introduce the benefits of using a Chameleon-developed trace generator for easily creating traces from cloud providers who use OpenStack.
No comments