Fair-CO2: Fair Attribution for Cloud Carbon Emissions
Understanding and accurately distributing responsibility for carbon emissions in cloud computing
- April 29, 2025 by
- Leo Han
Recent estimates by the International Energy Agency (IEA) indicate that datacenter energy use accounts for around 0.6% of global carbon emissions, with additional research from Microsoft suggesting that emissions from constructing data centers and hardware may be comparably significant. Many large data centers provide cloud services, enabling multiple applications to share resources, complicating accurate carbon footprint attribution to individual software workloads. However, precise carbon accounting is essential for cloud users aiming to reduce their climate impact.
Fair-CO2 addresses two key challenges. First, resource demands vary dynamically—workloads during peak periods significantly influence resource capacity and thus should carry higher carbon responsibility than off-peak workloads. Second, multiple workloads often share a single server, potentially causing interference and unfair emission attribution under current methods. Fair-CO2 seeks to fairly allocate carbon emissions by accounting for these complexities.
Research Overview
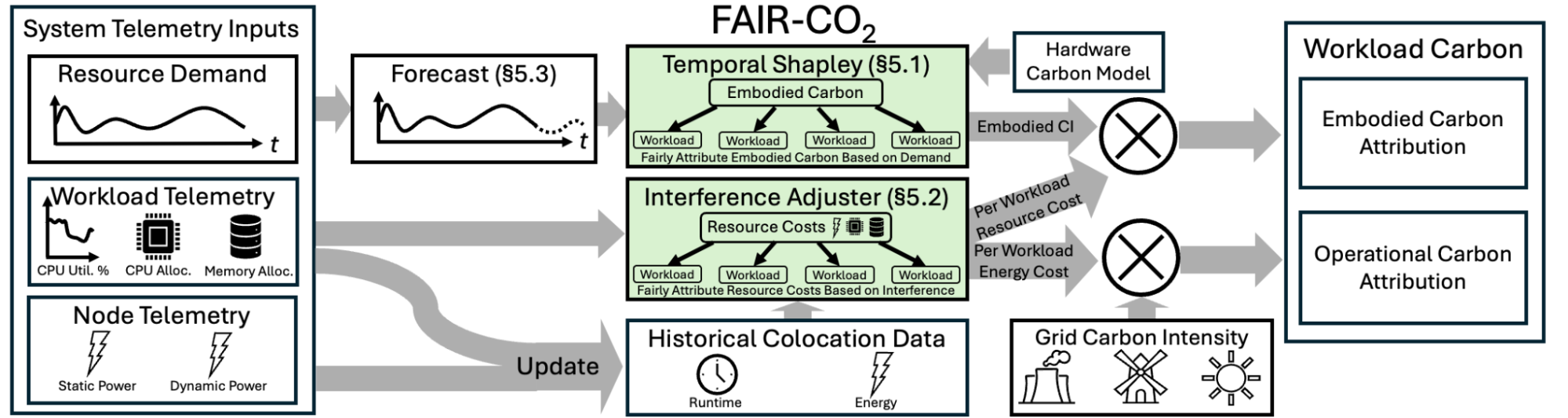
Our research proposes using the Shapley value from cooperative game theory as a principled ground truth for attributing carbon emissions in cloud data centers. The Shapley value is widely used in economics, infrastructure development, and computer systems to fairly divide shared costs. It evaluates all possible combinations of “players”—such as workloads or time intervals—and attributes impact based on each player’s average marginal contribution. It satisfies fairness properties like symmetry and efficiency, but computing it exactly is infeasible at cloud scale due to its exponential complexity.
To address this, we developed Fair-CO2, a scalable framework that approximates Shapley-based fairness in real time. Fair-CO2 solves two key challenges in current carbon dashboards: they ignore when a workload runs (e.g., peak vs. off-peak), and they overlook interference between colocated workloads. Fair-CO2 has two main components. First, Temporal Shapley treats each time slice as a player, attributing higher carbon intensity to high-demand periods. Second, an interference-aware adjustment uses historical telemetry to estimate how much a workload affects or is affected by others, refining its carbon attribution accordingly. The system ingests workload and system telemetry, applies these two components, and outputs a live carbon signal that can be queried by schedulers or billing tools.
To measure fairness, we use the Shapley distance—the percentage deviation from the true Shapley value. A lower distance means higher fairness. In over 20,000 simulated scenarios, Fair-CO2 achieved 4–5× lower Shapley distance than industry baselines, with only 1.7% average deviation compared to 9.7% for the baseline. Moreover, on one month of Microsoft Azure cloud data, Fair-CO2 is over 600,000× faster compared to the exact Shapley computation. Fair-CO2 brings accurate, real-time carbon attribution to cloud platforms, helping developers and organizations make greener, fairer decisions at scale.
Experiment Implementation on Chameleon
We used the provided Ubuntu 22.04 images from Chameleon and utilized the GUI to reserve and launch our instances. The hardware catalog was particularly helpful in identifying suitable hardware platforms that met the requirements of our experiment. Additionally, the host availability browser assisted us in scheduling our experiment dates according to resource availability and enabled us to make the necessary reservations. Bare-metal access was crucial to the success of our experiments, as we required detailed CPU performance counters to measure resource utilization and power consumption. Additionally, we needed the flexibility to configure kernel boot parameters during the development phase of our experiments. This capability was essential when testing both cgroups v1 and v2 configurations for our Docker containers.
Experiment Artifacts
Our research paper, “Fair-CO2: Fair Attribution for Cloud Carbon Emissions”, will be presented and published at the International Symposium on Computer Architecture (ISCA 2025) in Tokyo, Japan this June! We have also open sourced all of the code and scripts used to perform our experiments. You can access them either from the artifact on Zenodo or via our Github repository.
User Interview

Tell us a little bit about yourself I’m a second-year Ph.D. student at Cornell Tech, where I focus on research at the intersection of computer systems and sustainability. I’m broadly interested in how we can design and build more sustainable computing infrastructure in a world where technology is evolving rapidly. My recent work explores ways to make computer systems less carbon intensive, including research on uncertainty-ware hardware carbon modeling and fair carbon attribution. I’ve also started investigating how specialized hardware and systems can support higher-resolution and machine learning augmented climate models to enable more computationally efficient climate science. Looking ahead, I’m excited to continue working on innovative and impactful research—whether that takes the form of academic work, applied research in industry, or launching something entrepreneurial. My long-term goal is to help steer computing toward a more sustainable future. Outside of research, I enjoy playing table tennis, going to concerts, plays, and musicals, and playing the cello. These hobbies keep me energized and help me stay creative in my work.
Most powerful piece of advice for students beginning research or finding a new research project In my experience, the most powerful approach to starting research is to choose a direction or project based on a genuinely interesting problem—especially one where you have a hunch that there might be a meaningful research insight or solution. I try not to limit myself based on my existing skills or prior experience. Instead, I stay open to learning whatever new tools, methods, or knowledge are needed to fully engage with the problem. This mindset has helped me stay curious, adaptable, and motivated throughout my research journey.
How do you stay motivated through a long research project? To stay motivated through a long research project, I often revisit the original motivation and scope of the work. Reminding myself of the core problem I'm trying to solve helps me regain perspective, especially when I’ve been deep in the technical or engineering details for days or weeks. It’s easy to get bogged down by frustrating challenges, so grounding myself in the bigger picture is a useful reset. I also find that having consistent hobbies and making time for things I enjoy, even during the busiest weeks, preserves my sanity when the stress can otherwise be overwhelming. Lastly, when I feel stuck or unmotivated, I’ll step away and spend time doing unstructured learning—whether that’s reading a textbook, watching videos, or reading papers. These breaks help me reset creatively and often lead to new ideas or directions.
Why did you choose this direction of research? I chose this direction of research because it brings together two areas I care deeply about: computer systems and climate change. I find computer systems work technically fascinating—it sits at the intersection of hardware and software, and its broad applicability spans many domains. At the same time, I believe climate change is the most pressing existential challenge humanity will face this century. Computing technologies, particularly at the scale of modern infrastructure and emerging applications like AI, are both a contributor to and an enabler of solutions to that challenge. I was drawn to research at the intersection of computing and sustainability because I want to help reduce the environmental impact of computing while also exploring how we can harness its power to support solutions for climate change mitigation and adaptation.
Thank you for sharing your knowledge with the Chameleon community!
Power Patterns: Understanding the Energy Dynamics of I/O for Parallel Storage Configurations
Powering Through Data: Energy Insights for Parallel Storage Systems
- Sept. 30, 2024 by
- Maya Purohit
Learn how cutting-edge research is shedding light on the energy dynamics of I/O operations in HPC environments, potentially reshaping future storage designs.
Power Measurement and Management on Chameleon
Exploring Power Monitoring Techniques with RAPL, DCMI, and Scaphandre
- June 18, 2024 by
- Michael Sherman
Monitoring power consumption is crucial for understanding the energy efficiency of your applications and systems. In this post, we explore various techniques for measuring power usage on Chameleon nodes, including leveraging Intel's RAPL interface for fine-grained CPU and memory power data, utilizing IPMI's DCMI commands for system-level power information, and employing the Scaphandre tool for detailed per-process power monitoring and visualization. We provide practical examples and step-by-step instructions to help you get started with power measurement on Chameleon, enabling you to gain valuable insights into the energy footprint of your workloads.
Maximizing Performance in Distributed Systems with a Power Budget
- Oct. 15, 2019 by
- Huazhe Zhang
One challenge for power budgeting systems is how to power cap dependent applications for high performance. Existing approaches, however, have major limitations. Our work proposes a hierarchical, distributed, dynamic power management system for dependent applications.
No comments