Maximizing Performance in Distributed Systems with a Power Budget
- Oct. 15, 2019 by
- Huazhe Zhang
This work will be presented at Supercomputing 2019 in Denver, CO. The paper is nominated for both Best Paper Finalist and Best Student Paper Finalist. Visit Room 405 on Tuesday, Nov. 19 from 4:00-4:30 pm to learn more. For more information on the presentation: bit.ly/SC19PoDD. To read the entire paper: https://dl.acm.org/citation.cfm?id=3356174
Power capping has become indispensable for large-scale computing systems, such as data center, supercomputer. As these systems scale out, they are able to concurrently execute dependent applications that were serially processed previously. This reduces resource usage and execution time as they communicate at runtime instead of through disk. One challenge for power budgeting systems is how to power cap dependent applications for high performance. Existing approaches, however, have major limitations: (1) poor practicality, due to dependence on application profiles, (2)only optimize for power reallocation between nodes, without considering node-level optimization.
We propose Power-Capping Dependent Distributed Applications (PoDD) -- a hierarchical, distributed, dynamic power management system for dependent applications. We implement it on a 49-node chameleon cluster and compare it to SLURM, a state-of-the-art power management system, but not considering coupling, and PowerShift, a power capping system for dependent applications without node-level optimization. On average, PoDD increases performance over SLURM by 14-22%, over PowerShift by 11-13%.
Resources and Tools Required
1.Bare-metal(49) - one server, 48 client, and the 48 client servers are logically divided into frontend and backend, each has 24 nodes.
2.Appliance - NFS share. https://www.chameleoncloud.org/appliances/25/
3. RAPL interface - We rely on RAPL power monitor/capping interface to help handle node-level power limiting. As we find out, the haswell servers has the capping ability disabled in bios and Skylake one did not. So our experiment require skylake nodes. However, if software power capping techniques is used, instead of RAPL, then any micro-architecture should work.
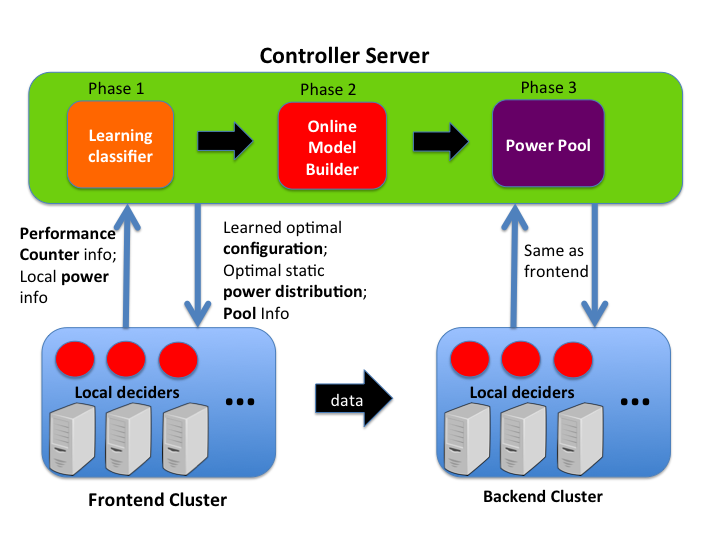
Experiment Procedure
For naming simplicity we refer to the two parts of an application couple as the front- and back-ends. The front-end produces data that is consumed by the back-end, so the couple represents a short pipeline. The couple’s overall performance will thus be determined by the slowest end, and an ideal resource management system would apportion resources such that each end takes the same time.
PoDD requires no offline profiling data or code instrumentation. PoDD operates in three phases: (1) classifying applications based on their optimal resource usage, (2) determining optimal power/performance tradeoffs for the coupled applications, and (3) dynamically adjusting power usage in an efficient, distributed manner to account for application phases, system noise, and tail behavior. PoDD amortizes overhead by dedicating one node to learning; all application nodes send performance counter information to the dedicated node, which coalesces the data and returns classification results for the coupled applications in the couple.
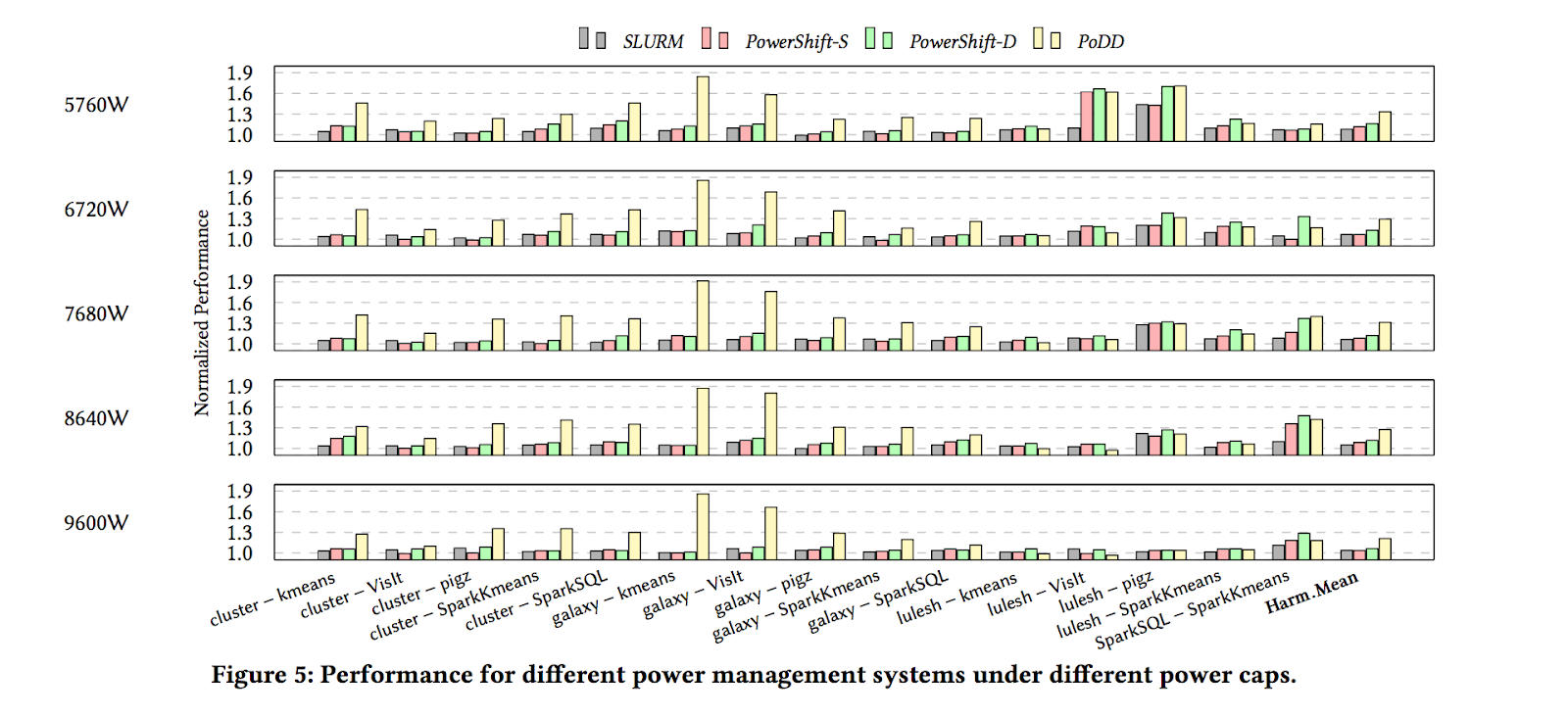
After setting up the Chameleon environment, benchmarks, libraries, simply launch each coupled application with PoDD power capping system and evaluate the performance by its runtime. One can also monitor the power consumption of the cluster to verify the power budget is respected. Figure below shows the performance delivered by each power management system across 5 power budgets for 11 coupled application pair. All numbers are normalized to Fair power management (allocate power evenly across nodes).
For our research, Chameleon testbed offers great ability to freely adjust hardware configurations (power capping, DVFS, core/memory affinity mask, etc) across many nodes. The scale and flexibility is what really makes our power management experiment possible.
This work is done at the University of Chicago, under the leadership of Dr. Henry Hoffmann.
Read more about the team here: https://people.cs.uchicago.edu/~hankhoffmann/seec/
Read the full paper here: https://dl.acm.org/citation.cfm?id=3356174
No comments