Zeus: GPU Energy as a First-Class Resource in DNN Training
- Nov. 22, 2022 by
- Jae-Won Chung
What is the central challenge/hypothesis your experiment investigates?
In recent years, Deep Neural Networks (DNNs) have become one of the most popular methods of implementing Artificial Intelligence (AI). The surge in DNNs was possible in large part due to a special type of hardware called GPU, traditionally built for graphics processing like gaming, but turning out to be very effective for the specific type of computation needed for training DNNs. Thus, to run DNN training, IT companies built large clusters of tens of thousands of GPUs, and the cluster is only getting larger.
What’s important is that GPUs are power-hungry hardware. They consume around 70% of the energy of the entire computer when training DNNs. At extreme scales, training a large DNN called GPT-3 just once consumes electricity that can supply an average US household for 120 years. This might be fine if DNN training is a one-time cost, but actually DNNs have to be re-trained, as frequently as every hour, to incorporate new data flowing in from users.
Hence we ask the question: How can we use less energy when training DNNs on GPUs?
How is your research addressing this challenge?
The first step of optimizing something (GPU energy in our case) would be to understand how it behaves when we change things. We decided that the most important knobs we have are the batch size used for DNN training and the power limit configuration of the GPU, both of which can be controlled with pure-software.
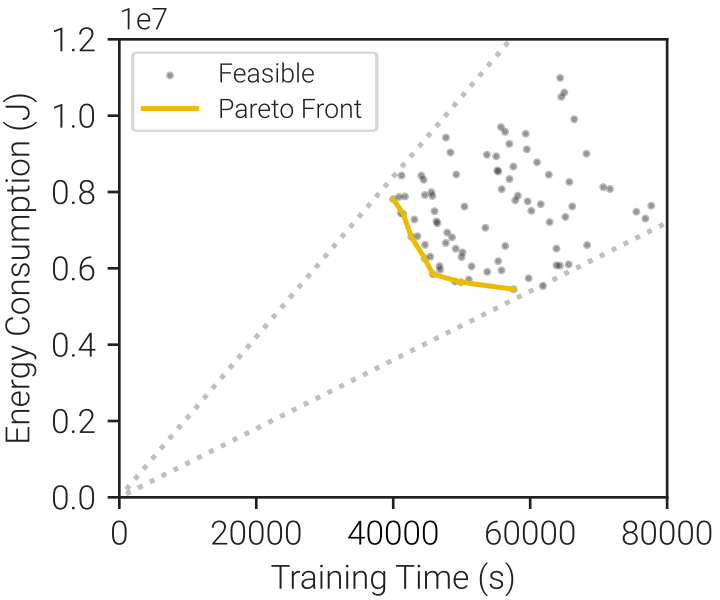
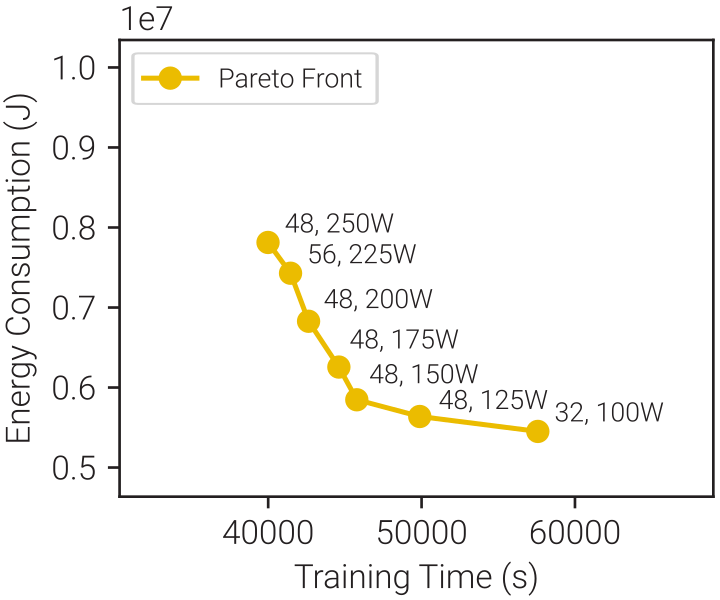
We swept all possible combinations of batch size and power limit, and found that there is a tradeoff between training time and energy consumption. The figure above shows a clear Pareto frontier of efficient training time and energy consumption pairs, each resulting from an efficient batch size and power limit pair.
Based on this understanding, we designed Zeus, an energy optimization framework for DNN training. Given an arbitrary DNN training job specification, Zeus can find the optimal batch size and power limit configuration that lies on the Pareto frontier
Zeus has two major components. First, the Just-in-Time power profiler transparently observes the power consumption of a DNN training job and figures out the optimal power limit while training is running. Second, the Multi-Armed Bandit module searches for the optimal batch size by observing and learning from the energy and time consumption of running training with certain batch sizes. Its goal is to figure out the optimal batch size without incurring too much cost while exploring, which is achieved by our modified version of the Thompson Sampling policy.
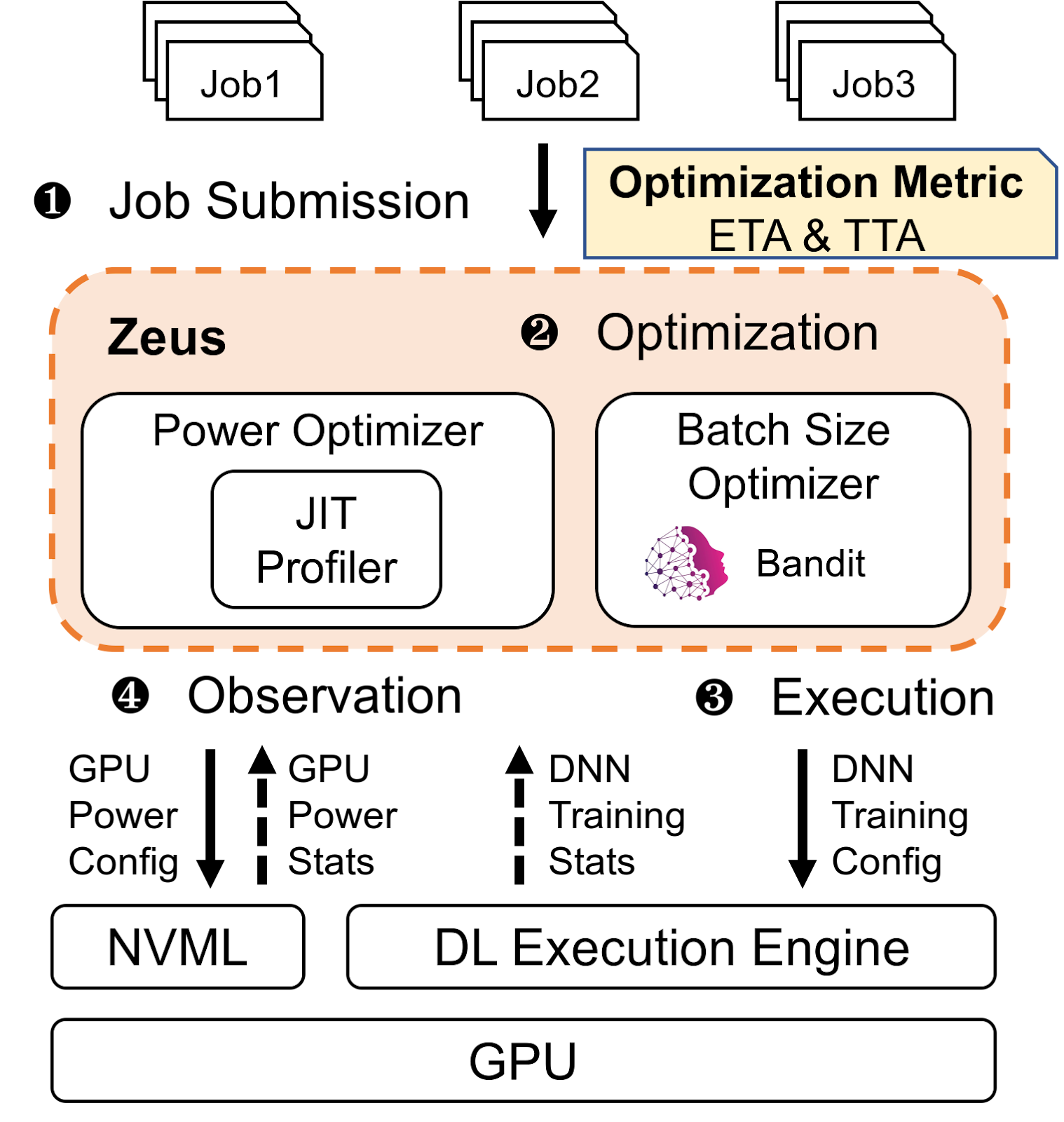
With all this, Zeus is able to cut down the energy consumption of DNN training by at least 15.3% and as much as 75.8%. Moreover, Zeus allows users to express their preferences of how much training time they’re willing to trade off for energy savings with a single number.
How do you structure your experiments on Chameleon?
Our project requires us to run the same workload on many different types of GPUs to show that our solution is general across GPU generations. Thankfully Chameleon Cloud offers many types of GPUs: NVIDIA A100, V100, P100, RTX6000, K80, M40, etc. Moreover, we can use the same operating system image (specifically we used the Ubuntu 20.04 CUDA 11 image) to create almost identical environments across machines with many different GPU types.
Now that we have the hardware, there is one special software I wrote to conveniently run hundreds of DNN training commands automatically across many machines over SSH. That software is Pegasus. Pegasus is a multi-node SSH command runner written in Rust that is well suited for any cloud service that provides simple SSH access to nodes. It allows you to 1) bootstrap multiple nodes at the same time by running the same sequence of commands, and 2) drain a queue of commands using a set of SSH nodes.
What features of the testbed do you need in order to implement your experiment?
Getting bare metal machines is a hard requirement for our experiments, because we are interested in the throughput and power consumption of GPUs. Any virtualization in between will influence the numbers in an undesirable way. Especially considering the diversity of our GPU type requirement, Chameleon Cloud was an integral part of conducting our experiments.
Can you point us to artifacts connected with your experiment that would be of interest to our readership?
Zeus was accepted to appear at the 20th USENIX Symposium on Networked Systems Design and Implementation (NSDI ’23). Zeus is completely open source, together with all the training and power consumption trace data we collected.
- Paper: https://arxiv.org/abs/2208.06102
- Website: https://ml.energy/zeus
- Open source repository: https://github.com/SymbioticLab/Zeus



Left to right: Jie You, Jae-Won Chung, and Mosharaf Chowdhury
Introducing the Zeus team, part of SymbioticLab in the University of Michigan!
Advised by associate professor Mosharaf Chowdhury, Jie and Jae-Won contributed equally to the publication of Zeus. Jie, who recently graduated as a PhD, is currently at Meta as a research scientist. Jae-Won (the writer of this blog post) is a second year PhD student interested in the intersection of deep learning and software systems. We are also leading the ML energy initiative, where Zeus is the first project under it.
Most powerful piece of advice for students beginning research or finding a new research project?
It doesn’t work until it works. Believe in what you do. And somehow if you find yourself not believing in what you’re doing (e.g. “Ugh, I don’t think this thing will ever work”), figure out why you’re feeling like that and try to resolve that issue.
How do you stay motivated through a long research project?
When things are going well, you don’t need to do anything to stay motivated. On the other hand, when you’re stuck, I think remembering the time when things went well and believing that you’ll make a breakthrough are important. Also, I always ask myself whether what I’m doing is fun and meaningful, and make sure the answer is always yes.
Why did you choose this direction of research?
My research experience begins with deep learning, not systems. But as I worked on deep learning, I realized that deep learning research is usually bottlenecked by systems, not how fast a researcher can generate ideas. That’s how I was motivated to delve into systems support for deep learning. I believe my experience in deep learning in turn helped a lot in making MLSys papers interesting and practical.
I dived into energy after I came to Michigan, which was something frequently optimized in the perspective of designing better hardware, but scarcely so in designing software. I believe this is an important topic because people already bought their hardware for deep learning (GPUs), and they’re not going to throw them away to replace them with more energy efficient hardware. We need a solution that is energy efficient on existing hardware, but flexible enough to be deployed without requiring significant modifications to any existing software stack.
No comments