A Statistics-Based Performance Testing Methodology for Cloud Applications
- Sept. 20, 2021 by
- Wei Wang
University of Texas, San Antonio Professor Wei Wang and PhD student Sen He investigate performance testing for cloud computing research to help make your research more efficient and cost effective. Learn about their research, which won the ACM SIGSOFT Distinguished Paper award in 2019, experience on Chameleon and AWS, and life philosophies.
On the current research:
Cloud computing has become the major computing infrastructure of our society. The average annual investment on cloud computing per organization is about $73.8 million, according to IDG’s 2020 cloud survey. To effectively utilize cloud resources, especially for planning resource allocation and autoscaling, users need to accurately measure the performance of their applications through performance testing. Without accurate performance information, a cloud user may spend more than 10 times on cloud resources than they actually need. However, applications’ performance in the cloud usually fluctuates randomly due to resource contention caused by multi-tenancy. This fluctuation makes it very difficult to accurately determine the performance of cloud applications.
The following figure shows the performance distributions of a cloud application obtained from two separate performance tests. The large difference between the two tests illustrates the difficulty of performance testing in the cloud -- at least one of them is inaccurate -- maybe both!
Figure 1. Example of Performance Tests Result Variations. This figure shows the performance distributions (probability density function, PDF) of the two performance tests.
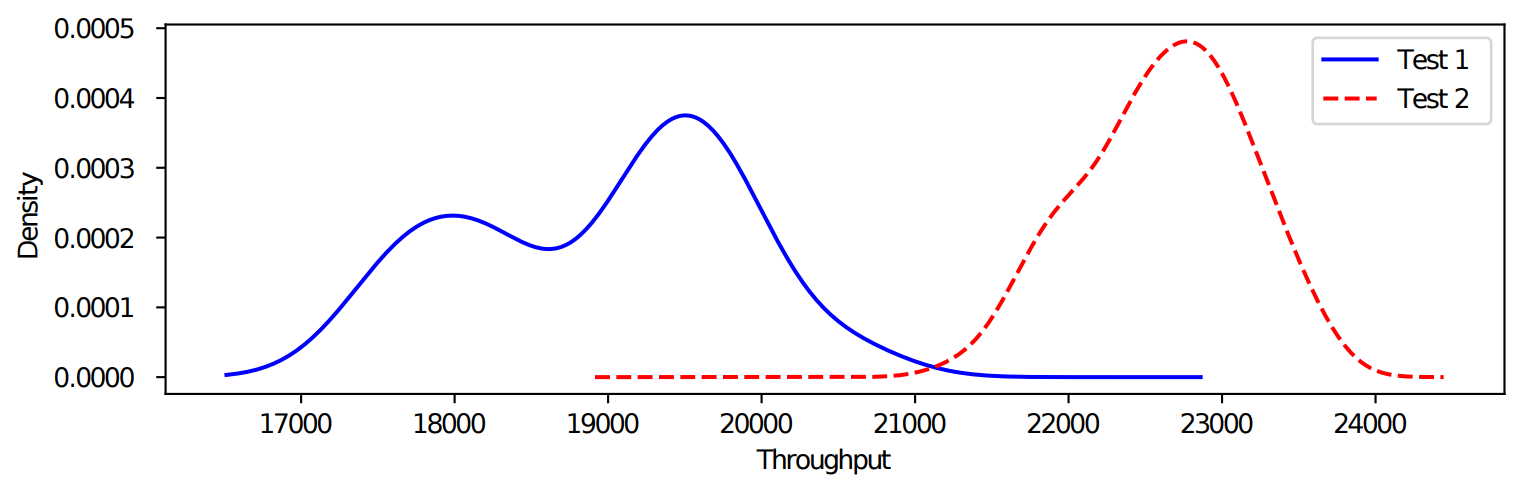
In short, cloud application performance is a fundamental requirement for efficient and effective cloud practice. This requirement applies to any cloud application scenarios, such as commercial software, web services and scientific computing. However, how to accurately obtain this performance is still an open research question.
We are building reliable performance testing methodologies that can provide accurate performance results while also maintaining low testing costs. Performance testing is essentially executing the application-under-test (AUT) repeatedly until accurate results are obtained. Therefore, the main research question is “how can we reliably know if the data from performance tests is accurate enough so that we can stop the test?”
This project is a collaboration project with Dr. Lori Pollock from University of Delaware and Dr. Mary Lou Soffa from University of Virginia.
On approaching the research challenge: The basic idea is statistical stability -- when the performance distribution calculated from the performance testing data is stable (does not change), then we know the performance distribution is most likely to be accurate, and the test can be stopped.
However, the real challenge is to determine when the performance distribution is stable. We need an approach that can quantitatively describe this stability, and we need to be able to handle the non-typical types of cloud performance distributions.
We relied on advanced statistical tools to aid the performance testing processing. More specially, we use nonparametric statistical tools -- we use multinomial likelihood to compute the probability that the performance distribution is stable, and we use bootstrapping to handle the non-typical distributions.
Figure 2. The overall flow of PT4Cloud
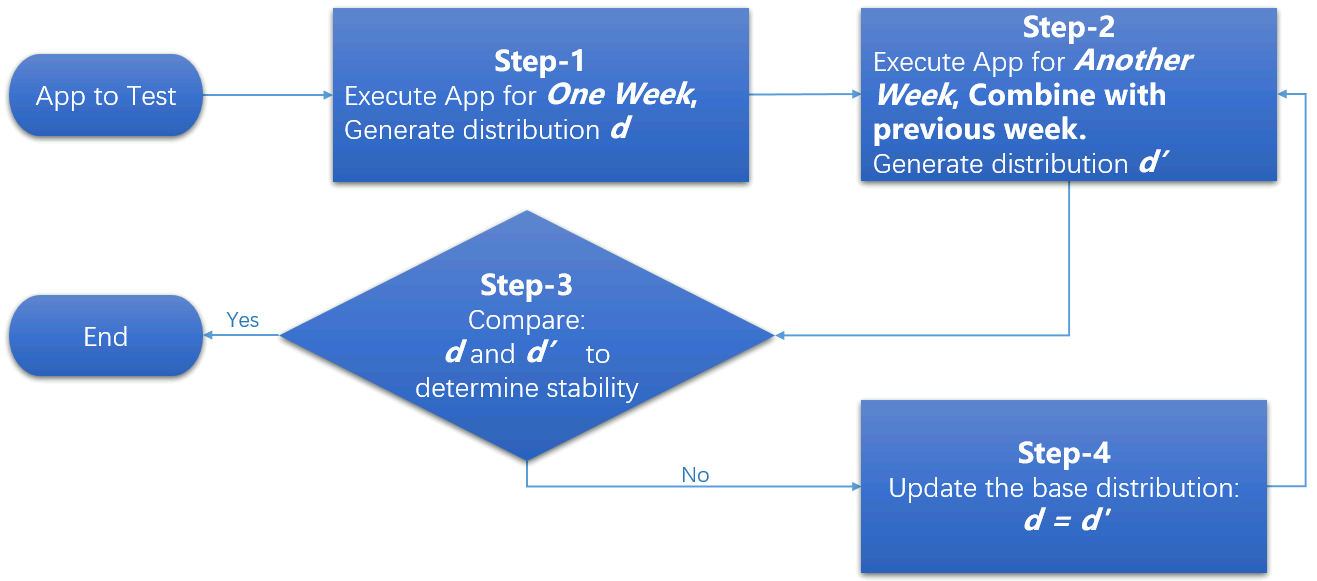
With the above ideas, the methodology we developed is called PT4Cloud. PT4Cloud conducts performance tests in multiple time periods of test runs. The application is executed repeatedly to collect n performance samples within each time period. Then, PT4Cloud calculates and determines if adding newly obtained n samples from the current time period significantly changes the performance distribution generated from previous periods. If the change is significant, more test runs of another time period are required. Otherwise, the performance distribution is considered stable and can be used to represent the actual performance distribution of the application on the cloud.
Figure 3. An example of PT4Cloud obtaining performance results with 92% stable probability after three weeks of performance tests.
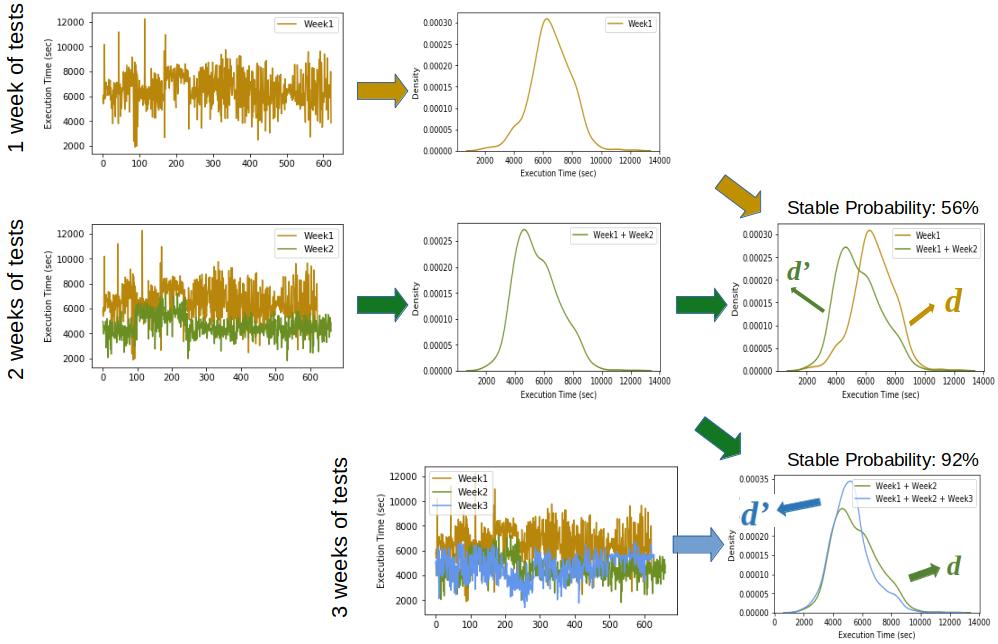
The above figure shows how PT4Cloud is used to obtain the performance results with 92% stable probability after three weeks of performance tests. In the figure, the first two weeks of tests have a stable probability of 56%. However, adding the third week increases the stable probability to 92%.
On testbed needs:
We mainly used Chameleon to validate our performance testing methodologies. We are probably in the rare group of users who rely more on the KVM setups than the bare-metal setups, although we do use bare-metal setups as benchmarking clients. The main benefits of Chameleon we appreciate are its scalability, free, and direct access. //On Chameleon, we tested 15 benchmark configurations consecutively executed for more than two months. Over 40 KVM instances of different VM flavors and over 20 bare-metal instances were simultaneously used. Without the large scalability from Chameleon, it is basically impossible for us to finish that many experiments within six months. Chameleon is a well-maintained cloud platform with a large user base, and therefore performance testing on Chameleon can represent the complicated random resource contentions of most cloud environments.
The second benefit is direct availability at no cost to the researcher. Chameleon is free for research. We actually conducted the experiments on both AWS and Chameleon to verify the effectiveness and efficiency of our methodology. The experiments on AWS cost us about $10,000, which was paid through our NSF grant. Besides the high cost, estimating AWS expense is more difficult because of the “hidden costs”, such as network usage and storage cost. These hidden costs are more difficult to accurately estimate the expense before experimentation. We are currently working on serverless performance testing, where the cost model is even more complex and difficult to plan with. Moreover, most of the cost on AWS was used to collect ground truth for evaluating PT4Cloud, which also shows the importance of inventing low-cost and accurate cloud performance testing methodologies.
On the authors:

Sen He is a Ph.D. student in the Department of Computer Science at the University of Texas at San Antonio. He has been working with Dr. Wei Wang since 2016. Sen He’s research interests include the areas of cloud computing, software engineering, and software testing. More specifically, his research is about using statistical tools to develop performance testing methodologies to obtain accurate performance results at reduced testing costs.

Wei Wang is an assistant professor in the Department of Computer Science at the University of Texas at San Antonio. He received his Ph.D. from University of Virginia in 2015. His research falls in the intersection of computer systems, cloud computing, computer architecture, and software engineering. His current projects mainly focus on cloud system designs, cloud native applications, and cloud performance engineering. His work was published in top CS conferences, including HPCA, MICRO, ASPLOS, PLDI, ICS, and FSE.
On staying motivated through a long research project:
Through a long research project, I don’t always stay motivated. I usually itemize the tasks and keep working. After each task is done, the sense of fulfillment will naturally motivate me through the next one.
On choosing his research direction:
Performance is one of the most important things users care about. I want to help users to easily and reliably obtain the performance without too much testing cost.
On his most powerful piece of advice:
I think it is important to work in an area that has direct and clear social impact. The project itself can start small, but it is important to think about how your future research can benefit society.
Interested readers can explore the following resources for more information:
Paper:
Software and Data:
Awards:
- ACM SIGSOFT Distinguished Paper Award
No comments