High School Summer Research Students at NYU Investigate Cloud and Edge Inference on Chameleon
Exploring Cloud and Edge Inference: High School Students' Journey Through Machine Learning Research with Chameleon at NYU
- Nov. 20, 2023 by
- Nana Ama Gyamfi-Kordie

There are many applications of machine learning in which a fast response time is essential. For example, in an agricultural setting where autonomous robots and humans may interact, a moving robot needs to be able to detect and locate a nearby human in time to stop or change its trajectory. Similarly, if machine learning is used to assist human surgeons in real time in the operating room, the automated feedback is only useful if it comes very quickly.
There are several elements that go into determining the response time: the type of compute resource used (edge or cloud, whether or not hardware acceleration on GPU or TPU is available), the network over which input data and predictions are transferred (e.g. its data rate, latency, jitter, and packet loss), the machine learning model and the framework in which the model runs (e.g. whether it is optimized for fast inference).
In our research, we evaluate the tradeoffs associated with these in a realistic setting representative of the two specific applications mentioned above - human-machine interaction in agriculture, and real time assistance in the operating room. We chose these two applications because very fast inference time is required in both.
Experiment: Research Methods and Challenges
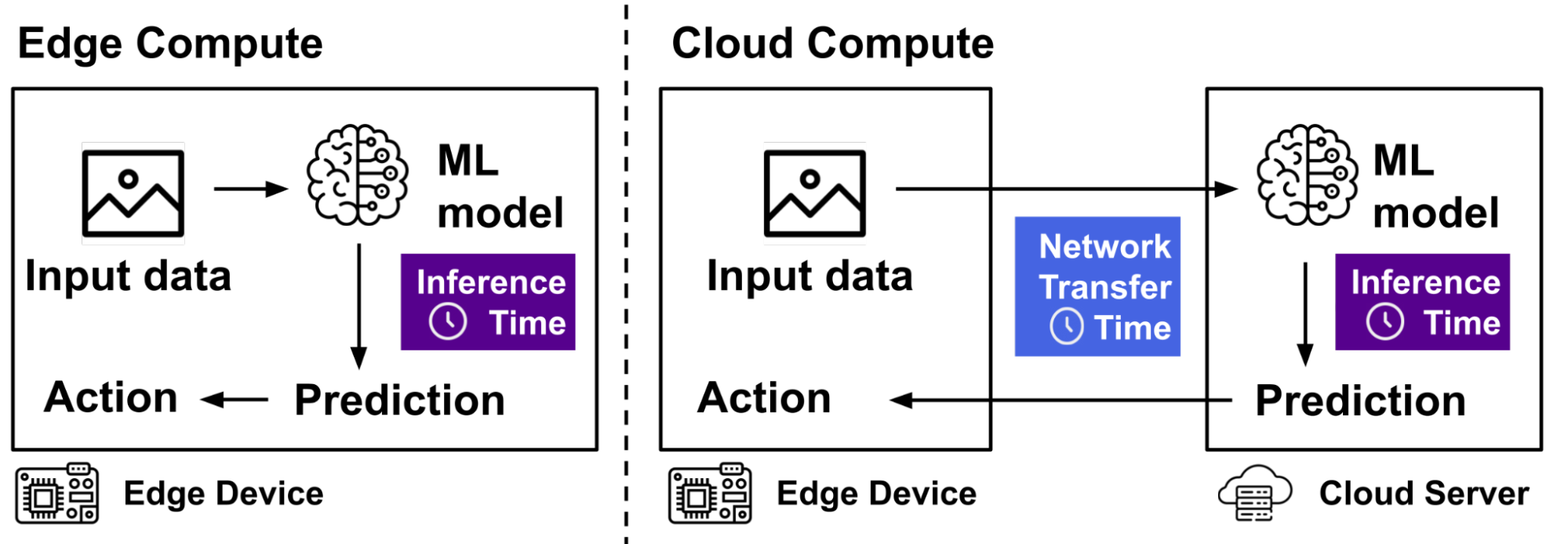
We wanted to investigate these performance tradeoffs under realistic circumstances for each application. First, we identify a dataset that is representative of each application – for the agricultural application, we used the NREC Person Detection Dataset, which consists of photos from apple and orange orchards, and, for the surgical application, we used the SARAS-MESAD Multi-Domain Endoscopic Surgeon Action Detection Dataset. We trained a lightweight machine learning model for each dataset. Then, we converted this model to different formats - we have a basic Tensorflow model, one that is optimized for NVIDIA GPUs using TensorRT, one that is designed to run in the TFLite framework on edge devices, and one that is compiled for Edge TPU devices. We used these models to measure inference time on CHI@Edge devices and CHI@UC cloud servers.
To measure network transfer time, we used network emulation on a line topology at KVM@TACC to make our network "mimic" the setting we were interested in – for the agricultural example, we emulated a mmWave wireless link under different blockage scenarios using previously collected traces, and, for the surgical example, we emulated two types of local area networks. Then, we transferred our actual test images from the dataset over the link and measured the network transfer time.
Our findings show that, as expected, the hardware acceleration (GPU or TPU) makes inference time much faster. However, the network transfer time is highly variable and depends very much on the setting. In the agricultural setting with a high-speed mmWave link, the total response time for a cloud GPU result (with both inference and network transfer) is still much faster than an edge CPU result. In the surgical setting, with a standard LAN, the response time for a Raspberry Pi 4 CPU result can be faster than a cloud GPU result.
Experiment: Implementation
Patterns
Our experiment is based on several education-focused experiments that are available on Trovi.
- Edge CPU Inference: This experiment shows how to deploy a container on a CHI@Edge device (for example, a Raspberry Pi 4), copy a machine learning model, labels, and test image to the device, and then run a single inference and time it. We replaced the model, labels, and test image that are included in the experiment with our own TFLite model to measure its inference time on an edge CPU device.
- Cloud GPU Inference: This experiment shows how to launch a cloud server with GPU on CHI@UC, install machine learning libraries (including TensorRT for optimized inference), copy a machine learning model, labels, and test image to the device, and then run a single inference and time it. It also shows how to optimize the model with TensorRT and measure the inference time of the optimized model. We replaced the model, labels, and test image that are included in the experiment with our own Keras/Tensorflow model to measure its inference time on a cloud GPU device, with and without TensorRT optimizations.
- Network Emulation: This experiment shows how to launch three virtual machines in a line topology at KVM@TACC, set up a network, and then emulate different data rates, delay, jitter, and packet loss settings across the network. In order to have meaningful results, we wanted to realize a network transfer time that would be representative of what might be available for the specific applications, so we used network emulation. For the agricultural example, we assumed the setting would be a private 5G mmWave network, and we "played back" the data rate measured over a real mmWave wireless link. For the surgical example, we configured the network to have settings representative of two types of LANs. In both examples, we uploaded our test samples and ran a server on one endpoint, then used the second endpoint to retrieve our test samples across the network, while measuring the transfer time.
Hardware
In our experiment, we needed a cloud server with GPU (we used RTX6000 nodes at CHI@UC), a Raspberry Pi 4 (available at CHI@Edge), and a high-speed network in a line topology (we used VMs at KVM@TACC). We also did some experiments on Coral Dev Boards, which are not yet available on CHI@Edge.
Artifacts
Our experiment materials (trained models, additional instructions) and poster are available on Github:
- Evaluating Edge & Cloud Computing in the Operating Room (Nana Ama)
- Evaluating Edge & Cloud Computing for Automation in Agriculture (Alberto)
About the Authors
Alberto Najera

I’m attending University Heights High School in the Bronx, New York, and during Summer 2023 I participated in the ARISE program at the NYU Tandon Center for K12 STEM Education. I’m still figuring out what I want to do for my career. I’m mainly interested in math and physics and would hope to possibly conduct research after college in these subjects. Some of my hobbies are running track, playing the guitar, and watching movies.
Nana Ama Gyamfi-Kordie

I currently attend Democracy Prep Charter High School in Manhattan, New York, and during Summer 2023 I participated in the ARISE program at the NYU Tandon Center for K12 STEM Education. I am a high school student who aspires to be a biomedical engineer. I hope to one day be in a lab designing software for medical equipment and I’m in love with arts and crafts, so I partake in 3D printing, painting and assembling lego sets.
Author Interview
What is your most powerful piece of advice for students beginning research or finding a new research project?
Alberto: You should always be trying to learn more - read more, know more. You can't ever have read enough or known enough.
Nana Ama: Debugging might take up all your time, but it builds character and knowledge. Great research doesn’t come easy!
How do you stay motivated through a long research project?
Nana Ama: Thinking about how there’s going to be an end product was my motivation. It made me continuously notice that there’s a goal to reach and that all those long hard hours aren’t for nothing.
Are there any researchers you admire? Can you describe why?
Nana Ama: I admire Sheila Atieno. She is a Black female biomedical engineer that I met through the NYU ARISE program. She has been one of the only few biomedical engineers I’ve ever met and has accomplished so much. She’s done research in synthetic genomics and cell programming and worked with topics like CRISPR. I see myself doing similar things, so seeing that it is tangible makes her an inspiration.
What has been a tough moment for you either in your life or throughout your career? How did you deal with it? How did it influence your future work direction?
Alberto: One thing I learned a long time ago, but continues to influence the way I work, is to know when to ask questions. You should always try to challenge yourself and figure it out on your own but you should know when to ask someone for help.
Why did you choose this direction of research?
Alberto: I have a bit of experience in Electrical Engineering and I wanted to continue to learn about it so I can figure out what I want to do in the future.
Thank you, Alberto and Nana Ama, for sharing your knowledge with the Chameleon community!
No comments