OneDataShare: Democratizing Access to Data
- June 21, 2023 by
- Jacob Goldverg
What is the central challenge your experiments investigate?
As data volumes in remote storage continue to grow, efficient and rapid access to this data becomes increasingly crucial. Existing tools such as rclone, rsync, and sftp face significant performance limitations when it comes to big data file transfers. In some cases, it may take weeks or be outright impossible to complete transfers using these standard Linux utilities. This is both unacceptable and inefficient, considering the significant compute and network resources allocated to researchers. Therefore, the question arises: How can we efficiently move large amounts of data while minimizing energy consumption, considering varying compute and network capacities?
How is your research addressing this challenge?
To enhance the energy efficiency of file transfers, OneDataShare(ODS) established an application-level monitoring framework that exposes control to the user or optimizer. This framework allows users and optimizers to assess network and host conditions and then appropriately exposes an API to adjust the tunable application parameters of the file transfer. ODS optimizers then gamify the file transfer process by adjusting parameters such as concurrent TCP connections, parallel TCP sockets, and network pipelining with the goal being to maximize throughput and minimize energy consumption. By doing so, optimizers gain control over CPU and network utilization, promoting energy efficiency. Overall, this approach revolutionizes file transfers, combining monitoring and gamification to optimize energy consumption and exposes a robust way to control file transfers in real time.
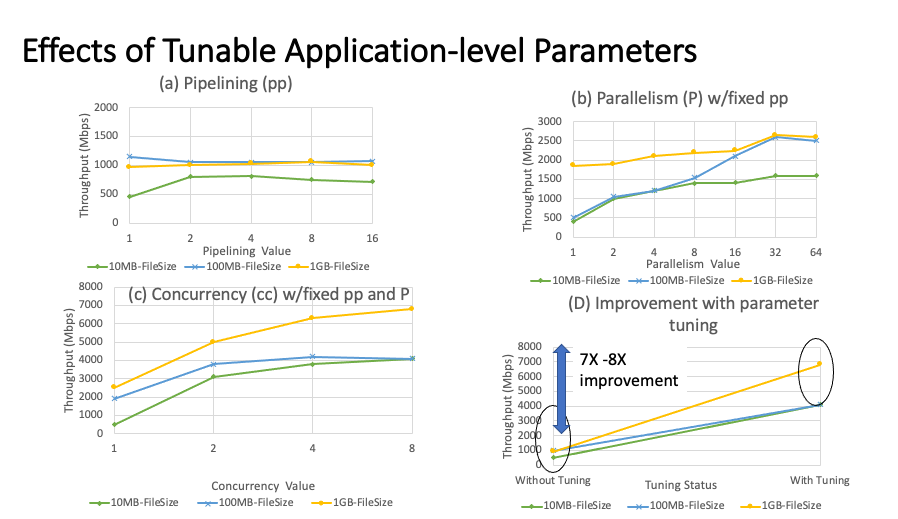
The following image depicts the impact the three application parameters have on the throughput of the file transfer. The challenge file transfers have faced in the past is the ideal number of concurrency, parallelism, and pipelining to maximize throughput, and what is the ideal tuple to be fair to the network. Our optimizers strive to reach the ideal point where throughput and network health converge.
![]()
Here, we demonstrate the data flow from the source server to the destination server. In scenarios where users are unable to install the File Transfer Service due to platform or permission limitations, ODS effectively optimizes the file transfer process for a variety of users.
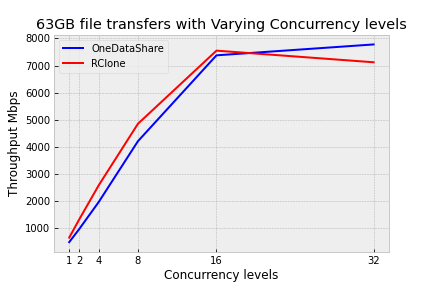
It is also crucial to consider the costs associated with implementing a monitoring and optimization service for file transfers, especially when users prefer not to utilize optimization. Therefore, we demonstrate that ODS achieves comparable performance and superior scalability to rclone even without optimization. This establishes ODS as an excellent platform for further optimization work.
The ultimate aim of this research is to empower users to transmit their large-scale data across the public internet without incurring exorbitant fees or relying on exclusive links or specialized computing resources.
How do you build your experiment on Chameleon?
Typical experiments that I run ODS involve deploying two nodes at UC and TACC where each node is connected over WAN or over a stitched network to control the topology. Chameleon has been instrumental in my experiments, thanks to two key features. The chameleon CLI offers extensive capabilities, surpassing those of the UI. This allowed me to automate lease creation, floating IP attachment, hardware deployment, and experiment execution through a single script. Additionally, the UI provides essential information about the leased hardware and site availability, ensuring I have all the necessary details at my fingertips.
What features of the testbed do you need in order to implement your experiment?
Chameleon Cloud meets the necessary requirements for ODS experimentation by providing a diverse set of bare metal compute nodes with varying size in network interfaces and CPUs. This allows for studying the impact of diminishing returns on different hardware and adjusting network interfaces and TCP parameters of the operating system. The availability of 10 Gbps and higher network interfaces enables HPC link experimentation. Moreover, Chameleon's ability to deploy software on instance start is very helpful as it helps alleviate the set up process for our experiments, some examples of what we use is NGINX, PostgresDB, and the Java runtime. I have also been exploring network stitching between Chameleon Cloud and FABRIC for efficient file transfers, taking advantage of FABRIC's ample network capacity.
Without Chameleon, experimentation would likely be limited to platforms like ACCESS (formerly XSEDE) and AWS, each with their own limitations in terms of usability and cost. XSEDE was challenging to use due to limitations in package installation forcing our experiments to use outdated packages and the limited documentation. It also offered a complex API making experiment reproducibility a real challenge. The limitation with using AWS is the inability to create a network topology across a large number of instances. The reason being in AWS we are forced to use private IP addresses to do communication which results in a lack of understanding the variance observed in the results due to network information not being publicly accessible. Chameleon Cloud exposes a concise API which allows for the full control and automation of the hardware we wish to measure, deploying the same network topology and then setting up the experimental data transfers all through the API.
Can you point us to artifacts connected with your experiment that would be of interest to our readership?
The ODS paper was published and since then the project has gone from a heuristic file transfer tool to an intelligent one with fine-grained monitoring and scheduling of file transfers. Its current form is hosted on onedatashare.org and offers the ability for users to launch, and monitor data transfers from the UI or the CLI. If you would like to learn more checkout our starter repository where we discuss more in depth on how ODS works and all of its core components and use cases.
Profile

Tell us a little bit about yourself
I am a second-year CSE PhD student at the University at Buffalo specializing in big data systems, high-performance computing, and networking. At the moment I am a research assistant under my advisor Dr. Tevfik Kosar. My research focuses on moving big data over a wide area network through efficient utilization of available resources like network and hardware through heuristic, machine learning, and reinforcement learning techniques in HPC sites and on the edge. Outside of academics, I enjoy baking, reading fantasy fiction, and camping.
Most powerful piece of advice for students beginning research or finding a new research project?
To start in research, it's crucial to follow your existing passions. During my Sophomore year of undergrad, I pursued an independent study with Dr. Kenneth Regan, focusing on chess games. We examined whether players at a certain rating were significantly outperforming their score. By analyzing improvement ratings per game, we aimed to determine if a player was likely cheating. This experience not only taught me game analysis but also programming, which was truly fascinating.
How do you stay motivated through a long research project?
Research is often considered difficult and challenging, but the fun aspects are often overlooked. Personally, my motivation stems from the enjoyment I find in the process. While this sense of fun may fluctuate, consciously focusing on the enjoyable parts helps alleviate stress associated with challenging aspects of the project.
Why did you choose this direction of research?
After completing my undergraduate degree, I faced a decision: pursue a career in industry as a Software Engineer or continue working on ODS. I opted for the PhD program because I recognized the importance of having the freedom to work on topics my advisor finds intriguing, which maximizes the enjoyment I derive from my work. Personally, I find building tools, particularly those capable of processing big data and utilizing large network links, to be fun. Furthermore, understanding the impact of the tools I develop adds an extra layer of fascination to the process.
Have you ever been in a situation where you couldn’t do an experiment that you wanted to do? What prevented you from doing it?
I began working on ODS about 4 years ago and encountered challenges when setting up experiments on commercial cloud providers. Specifically, I struggled with understanding the impact of data transfers on the network and CPU. When using virtualized hardware, I aimed to fully utilize the network capacity but found that my transfers were far from optimal. After diagnosing the issue with standard networking tools, I discovered that the rented network from AWS was virtualized, resulting in significantly lower capacity than the 1Gbps promised by the EC2 instance. As a result, I switched to providers like Chameleon Cloud.
No comments